PyTorch简介
1.Torch张量库介绍
深度学习的所有计算都是在张量上进行的,其中张量是一个可以被超过二维索引的矩阵的一般表示形式。稍后我们将详细讨论这意味着什么。首 先,我们先来看一下我们可以用张量来干什么。
# 作者: Robert Guthrie
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
1.1 创建张量
张量可以在Python list形式下通过torch.Tensor()函数创建。
# 利用给定数据创建一个torch.Tensor对象.这是一个一维向量
V_data = [1., 2., 3.]
V = torch.Tensor(V_data)
print(V)
# 创建一个矩阵
M_data = [[1., 2., 3.], [4., 5., 6]]
M = torch.Tensor(M_data)
print(M)
# 创建2x2x2形式的三维张量.
T_data = [[[1., 2.], [3., 4.]],
[[5., 6.], [7., 8.]]]
T = torch.Tensor(T_data)
print(T)
- 输出结果:
tensor([1., 2., 3.])
tensor([[1., 2., 3.],
[4., 5., 6.]])
tensor([[[1., 2.],
[3., 4.]],
[[5., 6.],
[7., 8.]]])
什么是三维张量?让我们这样想象。如果你有一个向量,那么对这个向量索引就会得到一个标量。如果你有一个矩阵,对这个矩阵索引那么就会 得到一个向量。如果你有一个三维张量,那么对其索引就会得到一个矩阵!
针对术语的说明:当我在本教程内使用“tensor”,它针对的是所有torch.Tensor对象。矩阵和向量是特殊的torch.Tensors,他们的维
度分别是1和2。当我说到三维张量,我会简洁的使用“3D tensor”。
# 索引V得到一个标量(0维张量)
print(V[0])
# 从向量V中获取一个数字
print(V[0].item())
# 索引M得到一个向量
print(M[0])
# 索引T得到一个矩阵
print(T[0])
- 输出结果:
tensor(1.)
1.0
tensor([1., 2., 3.])
tensor([[1., 2.],
[3., 4.]])
你也可以创建其他数据类型的tensors。默认的数据类型为浮点型。可以使用torch.LongTensor()来创建一个整数类型的张量。你可以在文
件中寻找更多的数据类型,但是浮点型和长整形是最常用的。
你可以使用torch.randn()创建一个张量。这个张量拥有随机数据和需要指定的维度。
x = torch.randn((3, 4, 5))
print(x)
- 输出结果:
tensor([[[-1.5256, -0.7502, -0.6540, -1.6095, -0.1002],
[-0.6092, -0.9798, -1.6091, -0.7121, 0.3037],
[-0.7773, -0.2515, -0.2223, 1.6871, 0.2284],
[ 0.4676, -0.6970, -1.1608, 0.6995, 0.1991]],
[[ 0.8657, 0.2444, -0.6629, 0.8073, 1.1017],
[-0.1759, -2.2456, -1.4465, 0.0612, -0.6177],
[-0.7981, -0.1316, 1.8793, -0.0721, 0.1578],
[-0.7735, 0.1991, 0.0457, 0.1530, -0.4757]],
[[-0.1110, 0.2927, -0.1578, -0.0288, 0.4533],
[ 1.1422, 0.2486, -1.7754, -0.0255, -1.0233],
[-0.5962, -1.0055, 0.4285, 1.4761, -1.7869],
[ 1.6103, -0.7040, -0.1853, -0.9962, -0.8313]]])
1.2 张量操作
你可以以你想要的方式操作张量。
x = torch.Tensor([1., 2., 3.])
y = torch.Tensor([4., 5., 6.])
z = x + y
print(z)
- 输出结果:
tensor([5., 7., 9.])
可以查阅文档获取大量可用操作的完整列表,这些操作不仅局限于数学操作范围。
接下来一个很有帮助的操作就是连接。
# 默认情况下, 它沿着第一个行进行连接 (连接行)
x_1 = torch.randn(2, 5)
y_1 = torch.randn(3, 5)
z_1 = torch.cat([x_1, y_1])
print(z_1)
# 连接列:
x_2 = torch.randn(2, 3)
y_2 = torch.randn(2, 5)
# 第二个参数指定了沿着哪条轴连接
z_2 = torch.cat([x_2, y_2], 1)
print(z_2)
# 如果你的tensors是不兼容的,torch会报错。取消注释来查看错误。
# torch.cat([x_1, x_2])
- 输出结果:
tensor([[-0.8029, 0.2366, 0.2857, 0.6898, -0.6331],
[ 0.8795, -0.6842, 0.4533, 0.2912, -0.8317],
[-0.5525, 0.6355, -0.3968, -0.6571, -1.6428],
[ 0.9803, -0.0421, -0.8206, 0.3133, -1.1352],
[ 0.3773, -0.2824, -2.5667, -1.4303, 0.5009]])
tensor([[ 0.5438, -0.4057, 1.1341, -0.1473, 0.6272, 1.0935, 0.0939, 1.2381],
[-1.1115, 0.3501, -0.7703, -1.3459, 0.5119, -0.6933, -0.1668, -0.9999]])
1.3 重构张量
使用.view()去重构张量。这是一个高频方法,因为许多神经网络的神经元对输入格式有明确的要求。你通常需要先将数据重构再输入到神经
元中。
x = torch.randn(2, 3, 4)
print(x)
print(x.view(2, 12)) # 重构为2行12列
# 同上。如果维度为-1,那么它的大小可以根据数据推断出来
print(x.view(2, -1))
- 输出结果:
tensor([[[ 0.4175, -0.2127, -0.8400, -0.4200],
[-0.6240, -0.9773, 0.8748, 0.9873],
[-0.0594, -2.4919, 0.2423, 0.2883]],
[[-0.1095, 0.3126, 1.5038, 0.5038],
[ 0.6223, -0.4481, -0.2856, 0.3880],
[-1.1435, -0.6512, -0.1032, 0.6937]]])
tensor([[ 0.4175, -0.2127, -0.8400, -0.4200, -0.6240, -0.9773, 0.8748, 0.9873,
-0.0594, -2.4919, 0.2423, 0.2883],
[-0.1095, 0.3126, 1.5038, 0.5038, 0.6223, -0.4481, -0.2856, 0.3880,
-1.1435, -0.6512, -0.1032, 0.6937]])
tensor([[ 0.4175, -0.2127, -0.8400, -0.4200, -0.6240, -0.9773, 0.8748, 0.9873,
-0.0594, -2.4919, 0.2423, 0.2883],
[-0.1095, 0.3126, 1.5038, 0.5038, 0.6223, -0.4481, -0.2856, 0.3880,
-1.1435, -0.6512, -0.1032, 0.6937]])
2.计算图和自动求导
计算图的思想对于有效率的深度学习编程是很重要的,因为它可以使你不必去自己写反向梯度传播。计算图只是简单地说明了如何将数据组合
在一起以输出结果。因为图完全指定了操作所包含的参数,因此它包含了足够的信息去求导。这可能听起来很模糊,所以让我们看看使用Pytorch
的基本标记(属性):requires_grad。
首先,从程序员的角度来思考。我们在上面刚刚创建的torch.Tensor对象中存储了什么?显然,是数据和结构,也很可能是其他的东西。
但是当我们将两个张量相加,我们得到了一个输出张量。这个输出所能体现出的只有数据和结构,并不能体现出是由两个张量加之和得到的
(因为它可能是从一个文件中读取的, 也可能是其他操作的结果等)。
如果requires_grad=True,张量对象可以一直跟踪它是如何创建的。让我们在实际中来看。
# 张量对象带有“requires_grad”标记
x =torch.Tensor([1., 2., 3], requires_grad=True)
# 通过requires_grad=True,您也可以做之前所有的操作。
y = torch.Tensor([4., 5., 6], requires_grad=True)
z = x + y
print(z)
# 但是z还有一些额外的东西.
print(z.grad_fn)
- 输出结果:
tensor([5., 7., 9.], grad_fn=<AddBackward0>)
<AddBackward0 object at 0x7fd66e2d9cf8>
既然变量知道怎么创建的它们。z知道它并非是从文件读取的,也不是乘法或指数或其他运算的结果。如果你继续跟踪z.grad_fn,你会从中
找到x和y的痕迹。
但是它如何帮助我们计算梯度?
# 我们来将z中所有项作和运算
s = z.sum()
print(s)
print(s.grad_fn)
- 输出结果:
tensor(21., grad_fn=<SumBackward0>)
<SumBackward0 object at 0x7fd73f1c7e48>
那么这个计算和对x的第一个分量的导数等于多少? 在数学上,我们求
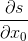
s是被作为张量z的和创建的。张量z是x+y的和,因此
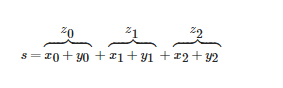
并且s包含了足够的信息去决定我们需要的导数为1!
当然它掩盖了如何计算导数的挑战。这是因为s携带了足够多的信息所以导数可以被计算。现实中,Pytorch 程序的开发人员用程序指令sum()和
+操作以知道如何计算它们的梯度并且运行反向传播算法。深入讨论此算法超出了本教程的范围.
让我们用Pytorch计算梯度,发现我们是对的:(注意如果你运行这个模块很多次,它的梯度会上升,这是因为Pytorch累积梯度渐变为.grad属
性,而且对于很多模型它是很方便的.)
# 在任意变量上使用 .backward()将会运行反向,从它开始.
s.backward()
print(x.grad)
- 输出结果;
tensor([1., 1., 1.])
作为一个成功的深度学习程序员了解下面的模块如何运行是至关重要的。
x = torch.randn((2, 2))
y = torch.randn((2, 2))
#用户创建的张量在默认情况下“requires_grad=False”
print(x.requires_grad, y.requires_grad)
z = x + y
# 你不能通过z反向传播。
print(z.grad_fn)
# “.requires_grad_( ... )”改变了“requires_grad”属性
# 如果没有指定,标记默认为True
x = x.requires_grad_()
y = y.requires_grad_()
#正如我们在上面看到的一样,z包含足够的信息计算梯度。
z = x + y
print(z.grad_fn)
# 如果任何操作的输入部分带有“requires_grad=True”那么输出就会变为:
print(z.requires_grad)
# 现在z有关于x,y的历史信息
# 我们可以获取它的值,将其从历史中分离出来吗?
new_z = z.detach()
# new_z有足够的信息反向传播至x和y吗?
# 答案是没有
print(new_z.grad_fn)
# 怎么会这样? “z.detach()”函数返回了一个与“z”相同存储的张量
#但是没有携带历史的计算信息。
# 它对于自己是如何计算得来的不知道任何事情。
# 从本质上讲,我们已经把这个变量从过去的历史中分离出来了。
- 输出结果:
False False
None
<AddBackward0 object at 0x7fd66c736470>
True
None
您也可以通过.requires_grad ``= True by wrapping the code block in ``with torch.no_grad():停止跟踪张量的历史记录中的自动
求导。
print(x.requires_grad)
print((x ** 2).requires_grad)
with torch.no_grad():
print((x ** 2).requires_grad)
- 输出结果:
True
True
False